Pacific Coastal and Marine Science Center
Bedform Sedimentology Site—ripples, dunes, and cross-bedding
|
Forecasting Techniques, Underlying Physics, and Applications
5.2 TechniquesSeveral techniques have been developed to use the approach outlined above to extract information about the nonlinear structure of a time series or spatial image (Farmer and Sidorowich, 1988; Sugihara and May, 1990; Casdagli, 1992; Rubin, 1992; Theiler et al., 1992; Theiler et al., 1994; Casdagli and Weigend, 1994; Sugihara, 1994). The underlying principle of such time-series forecasting is to predict future values of a time series by consulting a catalog of how the system evolved at other times when initial conditions were similar. Predictions are made by selecting an event (predictee) with a known history, searching the catalog for one or more events for which the recent time-history approximates the time-history of the predictee, and then using the next values of these k nearest neighbors in the catalog to predict the next value of the predictee. The idea of relating a sequence of past values of a time series to the future is based on physical principles, not merely statistical utility (Packard et al., 1980; Takens, 1981). The underlying principle is to use multiple values of a single variable to provide information about other variables that may be required to define the initial state of a physical system for which the future is to be predicted. As illustrated in the preceding discussion of equations 5.1 to 5.4, sequential values of one variable (such as location) can provide information about other variables (such as velocity). For a rigorous proof of this concept of embedding, see Takens (1981). For earth scientists who typically have a limited number of time series--often only a single time series--with which to understand a particular system, this ability to substitute one variable for several other variables seems almost too good to be true, if not pure magic. In practice, application of this principle is not so simple, because of the interaction of noise and delay time (time interval between values used in plotting an attractor, as defined in Chapter 4). If the chosen delay time is too short, the actual change in the time series is small, and even low levels of noise may mask the local structure of the attractor. On the other hand, if delay time is too large, then exponential divergence of trajectories means that the future state may have little or no relation to the first values in a sequence of lagged values used to represent the initial conditions. Forecasting begins by splitting a time series into two pieces. One piece (a catalog or learning set) is used to relate the recent history of the series to the next value in the series. The other piece (testing set) is used to test the predictive ability of the learning set. In this forecasting process, the recent history of the system for m steps through time t can be represented by a single point in m-dimensional space; the coordinates of that point are (xt-1, xt-2, xt-3 ... xt-m). To make each prediction, a predictee sequence of m values in the time series is placed (or embedded) in this m-dimensional space, and least squares is used to identify those m-dimensional sequences in the learning set that are closest to the predictee. This process is carried out computationally, but it can be visualized as plotting (in m-dimensional space) the point that represents the conditions for which a prediction is to be made and then locating the nearest points to this predictee; these nearby points represent other instances in the time series when conditions were most similar to the predictee. This process of locating these nearest neighbors can be visualized by another technique that is algebraically equivalent: graphically sliding the predictee sequence over a plot of the learning set time series and looking for the m-point sequences in the learning set that most closely match the predictee (for an example of this graphical approach, see Lendaris and Fraser, 1994). At least m+1 of these nearest neighbors are located, so that least squares can be used to solve
for the m+1 coefficients (a0...am) that best relate the future (xt) to the past (xt-1, xt-2, xt-3 ... xt-m) in the learning set. The second step in making each prediction requires that equation 5.5 be solved again, this time substituting the coordinates of the predictee (a different sequence of xt-1, xt-2, xt-3 ... xt-m but retaining the same values for the coefficients (a0...am). This second solution of equation 5.5 employs the relation determined from the learning set to predict xt for the testing set. To predict each point in the testing set therefore requires that equation 5.5 be solved twice (first to learn the values of the coefficients that best relate the past to the future in the learning set, second to use those coefficients and the predictee sequence to forecast the next value in the testing set). Model performance is then evaluated by comparing the predicted values with the actual values in the testing set. If the entire set of points in the learning set is used to evaluate the constants in equation 5.5, then the technique is simply a multiple linear regression. In the nonlinear technique, a smaller number of (different) nearest neighbors in the learning set are used to re-evaluate the constants (a0...am) for each prediction, thereby allowing equation 5.5 to effectively model nonlinear relationships using small locally linear pieces. Much of the knowledge learned from forecasting is obtained by exploratory computations employing a variety of models with different embedding dimensions (number of sequential values used to quantify the initial conditions for each predictee) or different numbers of nearest neighbors (number of similar sequences in the learning set used to evaluate the constants in equation 5.5 for each prediction). Two values can be used to quantify performance of these models: (1) correlation coefficient between predicted and observed values and (2) the normalized RMS error. E, the normalized RMS error of a model is given by
where j is the total number of predictions made for the testing set, e is the error for an individual prediction, and s is the standard deviation of the time series; for the forecasting technique to be meaningful, the time series must be stationary, requiring that be the standard deviation be equal for the testing and learning sets. A model that predicts each value perfectly has a normalized RMS error of zero and a correlation coefficient of 1.0, whereas a model that repeatedly predicts the mean value of the time series has a normalized RMS error of 1.0 and a correlation coefficient of zero. In practice, however, the correspondence between RMS error and correlation coefficient is not unique. For example, if each predicted value is exactly double the observed value, the correlation coefficient is 1.0, but the normalized RMS error is greater than zero. For this reason, RMS error is a more precise estimate of model performance. The correlation coefficient is nevertheless a useful measure of model performance, particularly where it is desirable to quantify the ability of the model to explain the variance of the time series (the amount of variance explained by the model is equal to the square of the correlation coefficient). One application of exploratory modeling is Casdagli's (1992) deterministic-versus-stochastic forecasting technique, which measures forecasting error as a function of the number of neighbors (similar events) used to make predictions. At one extreme (stochastic linear modeling), forecasts are based on behavior learned from all events in a learning set. This kind of global linear regression model maximizes noise reduction but minimizes sensitivity to the specific initial conditions for the event that is being forecast. At the other extreme (deterministic nonlinear modeling), forecasts are based on the relations learned from a small number of events for which the initial conditions are most similar to the event that is being forecast. In these nonlinear models, noise reduction is poorer, but sensitivity to initial conditions is enhanced. Casdagli (1992) argued that the dynamics of a system can be characterized by the class of model that makes the most accurate short-term forecasts. Low-dimensional nonlinear nonperiodicity (chaos) can be identified in systems where nonlinear models employing a small number of nearest neighbors and small embedding dimension outperform global linear models. In an exploratory search for nonlinearity, it may be advantageous to vary the forecasting time (the number of time steps from the end of the predictee sequence to the time for which a value is predicted), because the relative improvement of a nonlinear model may become more evident at prediction times greater than a single time step. As the prediction time continues to increase, all models may perform so poorly that it becomes difficult to detect an advantage of any model. In equation 5.5, the subscripts indicate a single step-ahead forecast, but the equation can be modified to describe a forecasting time of n time steps by substituting xt+1-(i+n) for xt-i. Another approach in forecasting has been to compare forecasts of an original time series with forecasts made from surrogate series (Theiler et al., 1992). The surrogates are created to mimic some, but not all, attributes of the original. For example, surrogates made to have power spectral magnitudes as the original--but having randomized phases--can be used to test the null hypothesis that the original time series is linearly correlated noise. If the original and surrogate time series have significantly different forecastability, then this hypothesis can be rejected; such results demonstrate that the original time series has a deterministic nonlinear structure that is not retained in the surrogates. Similarly, forecasting accuracy can be measured for models that vary the embedding dimension m, to evaluate the number of active degrees of freedom of a system from which a time series was sampled. For example, m must be at least three to accurately forecast the behavior of a system with three degrees of freedom, such as Lorenz's (1963) simplified model of convection (equation 2.13). If the value of m used to make forecasts for this system is less than three, then trajectories cross (as in the two-dimensional image of the attractor of the Lorenz system in Figure 2.1). Consequently, forecasts made for an intersection may be inaccurate, because the wrong trajectory is chosen. Increasing the embedding dimension eliminates these intersecting trajectories, and is said to "disambiguate" the data; accurate forecasts can now be made. By applying forecasting in an exploratory manner (performing computations to evaluate the relative performance of models with different embedding dimensions), a lower limit of the number of degrees of freedom can be evaluated. In this application, forecasting performs the same function as the false neighbors technique described in Chapter 4.3. Sugihara and May (1990) suggested using the decay (with time into the future) of forecasting accuracy to distinguish uncorrelated noise from chaos in time series. The idea behind this technique is that chaos can be predicted for short times into the future, whereas uncorrelated noise is unpredictable even for a single step in time. Although this technique can recognize the null case of uncorrelated noise, some of the more interesting null hypotheses (correlated noise or combinations of deterministic structure and correlated noise described by Rubin, 1992) can not be distinguished from chaos using this technique. Additional details of these modeling techniques are given by Casdagli (1992) and Casdagli and Weigend (1994); a computational algorithm for spatial forecasting is described by Rubin (1992). The knowledge to be gained from these forecasting techniques can be compared to that gained from spectral analysis. Both techniques provide information about how a system operates, but neither provides the specific equations that describe the system. Determining that a particular nonperiodic system is linear or nonlinear, like determining the dominant frequencies of a periodic system, is merely one step in characterizing or understanding the system. Continue to next section.
|

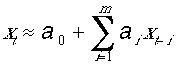 (5.5)
(5.5)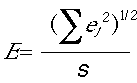 (5.6)
(5.6)